Over the course of 24 lectures, we learnt to use the SPSS software to analyse data and deduce meaningful interpretations from them. The course included general use of SPSS software to familiarise ourselves with the various tools available in SPSS. Some of the tools used for analysis are K-Means, Discrminant Analysis, Factorial Analysis, PerMap, Bubbles Graph, Chart Graph and Conjoint Analysis.
K-means clustering is a method of cluster analysis which aims to partition 'n' observations into 'k' clusters in which each observation belongs to the cluster with the nearest mean. It attempts to find the centers of natural clusters in the data as well as in the iterative refinement approach.
Discriminant analysis is a method used in statistics, pattern recognition and machine learning to find a linear combination of features which characterize or separate two or more classes of objects or events. The resulting combination may be used as a linear classifier, or, more commonly, for dimensionality reduction before later classification.
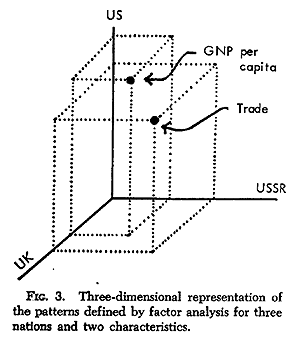
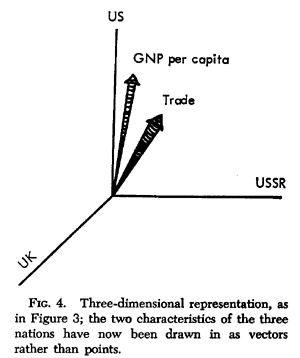
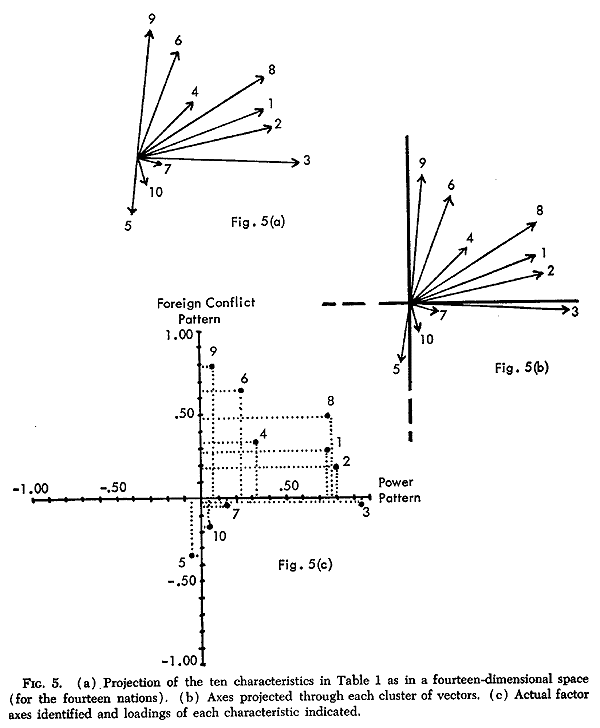
Factor analysis is a statistical method used to describe variability among observed variables in terms of a potentially lower number of unobserved variables called factors. Factor analysis searches for such joint variations in response to unobserved latent variables. The information gained about the interdependencies between observed variables can be used later to reduce the set of variables in a dataset.
Perceptual mapping is a graphics technique used by marketers that attempts to visually display the perceptions of customers or potential customers. Typically the position of a product, product line, brand, or company is displayed relative to their competition. Perceptual maps can have any number of dimensions but the most common is two dimensions.
A chart is a graphical representation of data, in which the data is represented by symbols. Charts are often used to ease understanding of large quantities of data and the relationships between parts of the data. Charts can usually be read more quickly than the raw data that they are produced from.
A bubble chart is a type of chart where each plotted entity is defined in terms of three distinct numeric parameters. Bubble charts can facilitate the understanding of the relationships between the different entities.
Conjoint analysis is a statistical technique used in market research to determine how people value different features that make up an individual product or service. The objective of conjoint analysis is to determine what combination of a limited number of attributes is most influential on respondent choice or decision making. A controlled set of potential products or services is shown to respondents and by analyzing how they make preferences between these products, the implicit valuation of the individual elements making up the product or service can be determined.
Author: Karthikeyan Dakshinamurthy (13081)
Group: Marketing - Group 4
K-means clustering is a method of cluster analysis which aims to partition 'n' observations into 'k' clusters in which each observation belongs to the cluster with the nearest mean. It attempts to find the centers of natural clusters in the data as well as in the iterative refinement approach.
Discriminant analysis is a method used in statistics, pattern recognition and machine learning to find a linear combination of features which characterize or separate two or more classes of objects or events. The resulting combination may be used as a linear classifier, or, more commonly, for dimensionality reduction before later classification.
Factor analysis is a statistical method used to describe variability among observed variables in terms of a potentially lower number of unobserved variables called factors. Factor analysis searches for such joint variations in response to unobserved latent variables. The information gained about the interdependencies between observed variables can be used later to reduce the set of variables in a dataset.
Perceptual mapping is a graphics technique used by marketers that attempts to visually display the perceptions of customers or potential customers. Typically the position of a product, product line, brand, or company is displayed relative to their competition. Perceptual maps can have any number of dimensions but the most common is two dimensions.
A chart is a graphical representation of data, in which the data is represented by symbols. Charts are often used to ease understanding of large quantities of data and the relationships between parts of the data. Charts can usually be read more quickly than the raw data that they are produced from.
A bubble chart is a type of chart where each plotted entity is defined in terms of three distinct numeric parameters. Bubble charts can facilitate the understanding of the relationships between the different entities.
Conjoint analysis is a statistical technique used in market research to determine how people value different features that make up an individual product or service. The objective of conjoint analysis is to determine what combination of a limited number of attributes is most influential on respondent choice or decision making. A controlled set of potential products or services is shown to respondents and by analyzing how they make preferences between these products, the implicit valuation of the individual elements making up the product or service can be determined.
Author: Karthikeyan Dakshinamurthy (13081)
Group: Marketing - Group 4




{kind=link}
{kind=link}
{kind=link}